The Power of Simple Models: Why Complexity Isn't Always the Answer
10 min
read
l
Vasudev Gupta
l
July 17, 2025


Let’s craft intelligent solutions together—turning your data into unstoppable growth.



Disclaimer: This article is not meant to diminish the incredible advancements being made with complex neural networks and AI models. As data science professionals, we deeply value and regularly implement sophisticated algorithms in appropriate contexts. The research community's work on advancing state-of-the-art AI is essential and transformative. This piece simply advocates for thoughtful model selection based on the specific problem at hand, recognizing that in some cases, simpler approaches may offer practical advantages.
In today's AI-driven landscape, there's a persistent narrative that more complex models yield better results. Social media, tech blogs, and YouTube tutorials bombard us with the same message:
"You should use Deep Learning™ & sophisticated Models" — Blogs, Reddit, Hacker News and YouTube Stars
But as a data science leader with years of experience implementing both simple and complex solutions, I've come to appreciate an often-overlooked truth: the elegance and practical power of simpler models. While deep learning and complex algorithms have their place, the hype surrounding them often distracts us from understanding the actual problems we're trying to solve.
Vincent D. Warmerdam captured this perfectly when he said:
"When you understand the solution of the problem better than the problem itself, then something is wrong!"
This insight cuts to the heart of effective data science. Too often, we become experts at implementing complex algorithms without truly grasping the nuances of the problem at hand. We reach for sophisticated tools not because the problem demands it, but because it's what we know or what will impress our peers.
In my experience leading data science teams, I've observed a concerning trend: people focus more on the tools they're using than the problems they're solving. This isn't to say complex models aren't amazing—they absolutely are—but the hype around them can lead us astray from simple, elegant solutions.
Let's look at a classic case that's used to dismiss linear models: the XOR problem.
Every machine learning textbook presents this as definitive proof that neural networks outperform standard regression. The argument is simple: linear models can only split data with a single line, while the XOR problem requires a non-linear solution because the dataset can't be separated by a single boundary.
This appears to be an open-and-shut case against linear models. But is it really?
When facing the XOR problem, our instinct is typically to reach for more complex algorithms—neural networks, SVMs with non-linear kernels, or other sophisticated approaches. These solutions work, but they come with drawbacks: reduced interpretability, implementation complexity, and potential maintenance headaches.
But what if we could solve the XOR problem with a simple linear model?
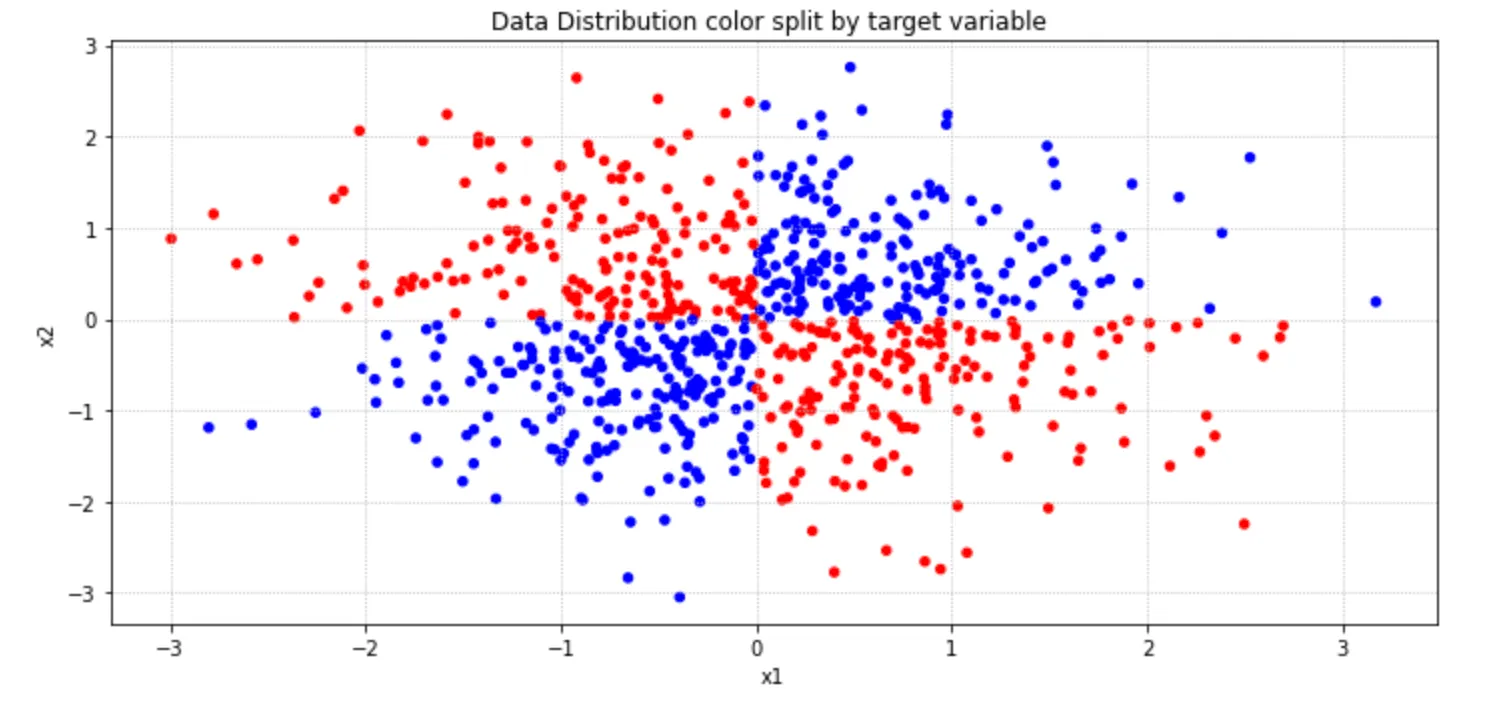
I ran an experiment demonstrating exactly this. Let's walk through the entire process, starting with creating our XOR dataset:
This creates our classic XOR pattern, where points in opposing quadrants share the same class. Looking at the plot, we can see the data isn't linearly separable with a single line.
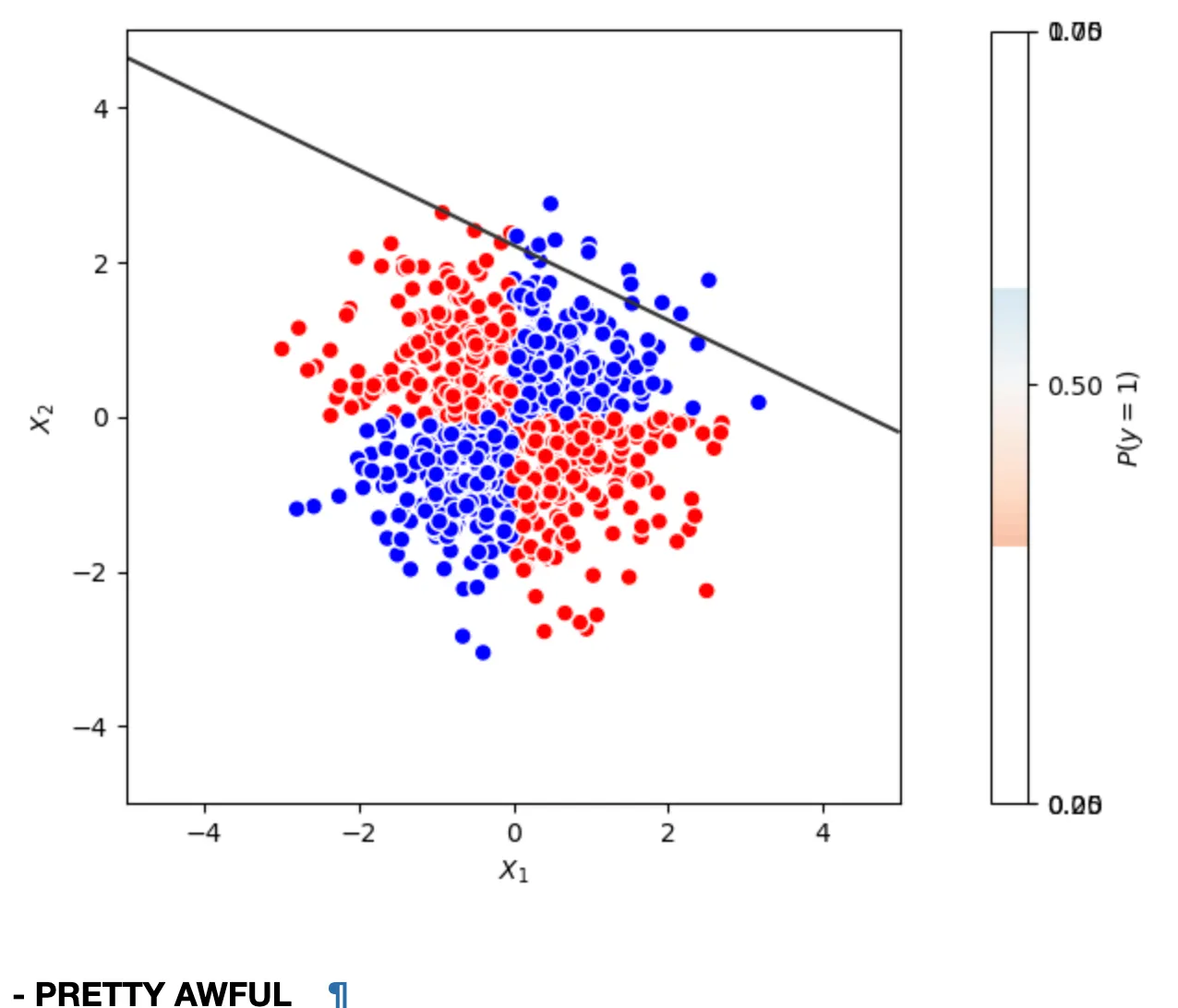
Next, I tried a standard logistic regression:
As expected, the model performed poorly, achieving only about 52% accuracy—barely better than random guessing. The decision boundary is simply a straight line, which can't capture the XOR pattern.
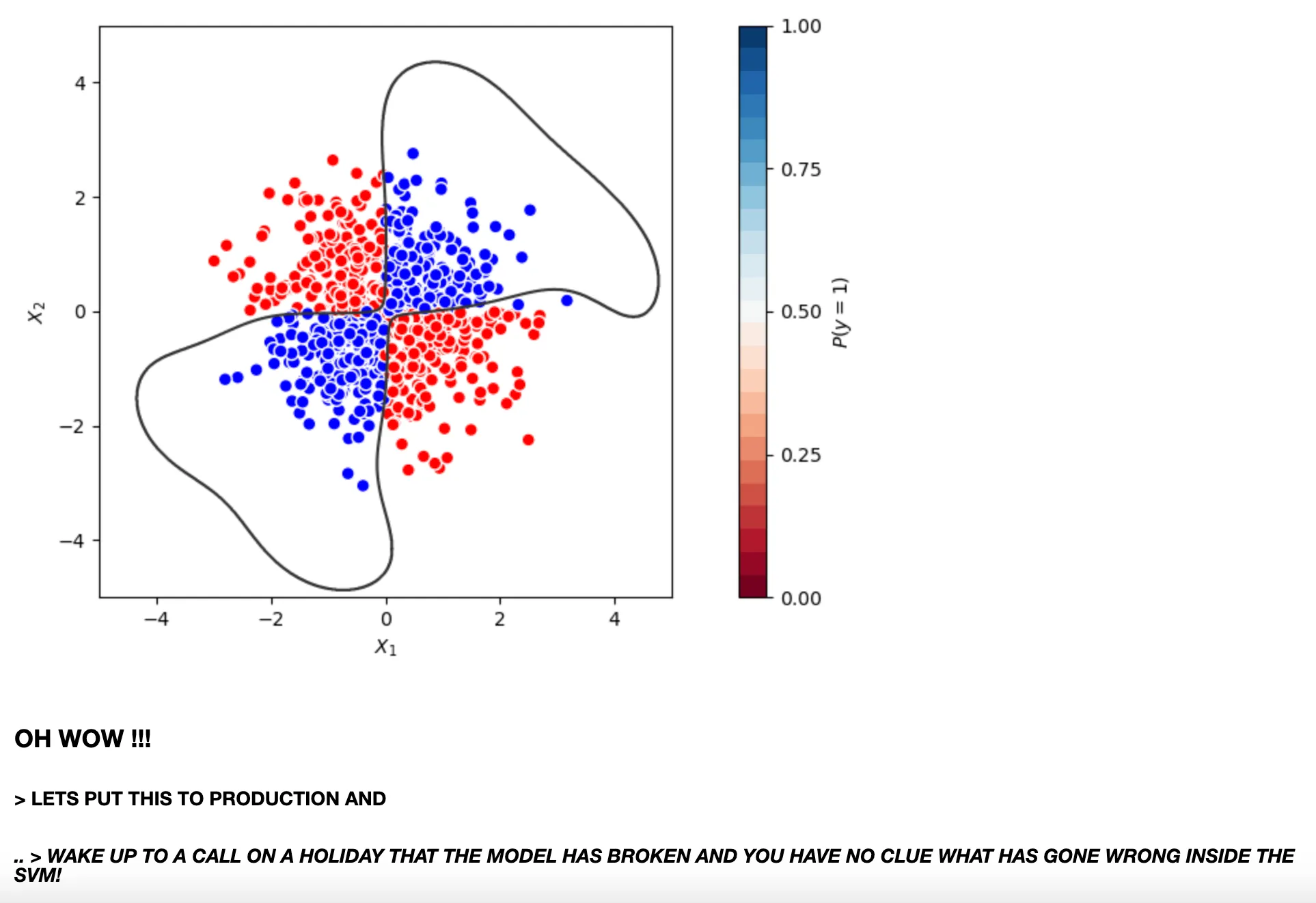
I then tried an SVM, which performed admirably:
The SVM achieved around 95% accuracy with a beautiful non-linear decision boundary that perfectly captured the XOR pattern. Success! But at what cost?
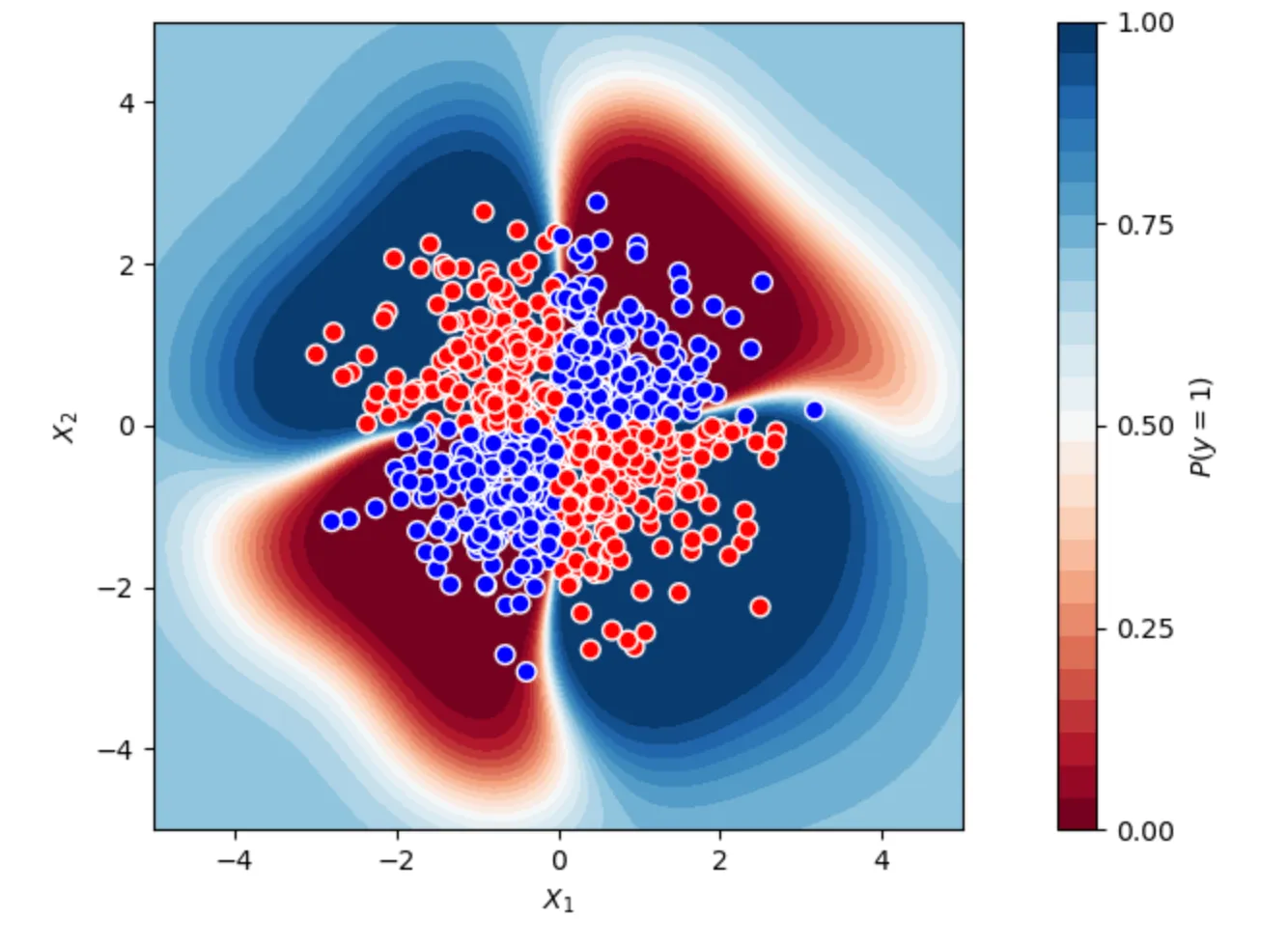
The SVM solution, while effective, is a black box. If it fails in production, diagnosing the issue would be challenging. Do we really need this complexity?
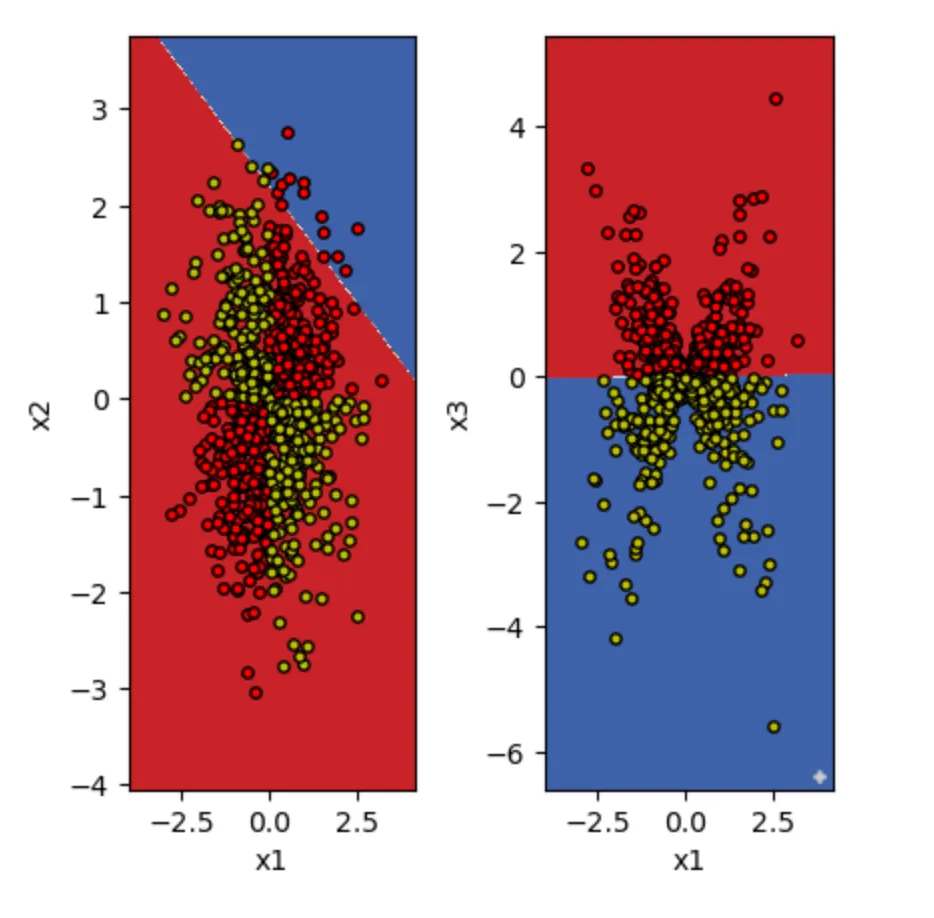
Here's where feature engineering shines. By adding just one new feature—the product of our existing features—we can transform the problem:
The result? An impressive 98% accuracy—even better than the SVM—while maintaining the interpretability and simplicity of a linear model. With just one additional feature, our linear model can now create a curved decision boundary that perfectly captures the XOR pattern.
This isn't just an academic exercise. In production environments, model properties beyond raw accuracy become critical:
As a consultant, I've found it's much easier to leave clients with a well-engineered linear model—especially if they're just beginning their modeling journey—than a complex black-box solution that might require specialized knowledge to maintain.
Of course, this doesn't mean we should never use complex models. Deep learning has revolutionized many domains for good reason. The key is to add complexity thoughtfully, only when:
The next time you approach a data problem, resist the immediate urge to reach for the latest algorithm. Instead:
And the next time someone says, "Oh, you've created a linear regression to solve this?" remember that your choice reflects wisdom, not limitation. You've focused on the problem rather than the solution—and that's something to be proud of.
It's not that deep learning and complex models aren't valuable—they absolutely are. But the hype around them can distract us from great ideas and simpler solutions that might be more appropriate for our specific problems.
As data scientists, our job isn't to implement algorithms—it's to solve problems. Sometimes, that means having the courage to embrace simplicity in a field that often rewards complexity.
So let's explore the domain of "boring, old but ultimately beautiful simple models" with fresh eyes. With thoughtful feature engineering and a solid understanding of our problems, we might find that the simplest solution is often the most elegant and effective one.
This blog was inspired by Vincent Warmerdam's PyData London 2018 talk "Winning with Simple, even Linear, Models" and my own experiences implementing these principles in production environments.